Pointer meters recognition method in the wild based on innovative deep learning techniques

On this part, our pointer detection methodology Pointer Indication Community (PIN) is described intimately in subsections “Pointer Indication Network (PIN)“, Coaching course of, and Loss operate, describing its community structure, coaching, and loss operate, respectively. Determine 2 reveals the proposed mannequin used on this examine.

An illustration of the PIN structure. There’s totally convolutional community. The enter picture is first processed by 5 encoders of the Encoder Community, then three decoders of the Decoder Community upsample its enter to extend the decision of function maps and the spatial dimension of extracted options. Lastly, the ultimate decoder output function maps are fed to the thing heatmap-scalarmap module to foretell a confidence heatmap and two scalar maps for pointer recognition, respectively.
Pointer indication community (PIN)
Determine 3 illustrates the community framework of PIN. The community framework of PIN could be represented as (P = left( E, A, D, Oright)), which consists of an encoder community E, an improved Convolutional Block Consideration Module (CBAM)33 A, a decoder community D, and a goal heatmap- scalarmap module, OHSM) O. Given a two-dimensional enter picture x of measurement (w occasions h) (w is the width and h is the size), the heatmap output (y_1) and scalarmap output (y_2) could be computed by:
$$start{aligned} y_1,y_2=Pleft( xright) =Oleft( Dleft( Eleft( xright) proper) +Aleft( E_1left( xright) +E_2left( xright) proper) proper) finish{aligned}$$
(1)
the place (E_1left( xright)) and (E_2left( xright)) are the low-level info generated by the primary encoder and the second encoder of the encoder community E, respectively, which include much less semantic info, and it’s straightforward for gradient explosion to happen by utilizing them instantly because the function detection layer34,35. Subsequently, these two low-level info layers are jump-connected into the improved CBAM to complement the shallow high-resolution, low semantic function info, clear up the shallow function info loss drawback, and enhance the convergence velocity of the mannequin36. The next factors describe every operation.

Structure particulars of Encoder Community. The CBR consists of a convolutional layer, batch normalization and ReLU activation operate. Apart from the primary encoder which has a convolution kernel measurement of (7 occasions 7), the opposite encoders all have a convolution kernel measurement of (3 occasions 3) and shortcut connection.
-
(1)
Encoder community E: So as to keep away from layer-by-layer function disappearance and accuracy degradation because the community depth will increase, every encoder of the encoder community employs a ResBlock37 with a residual construction, as proven in Fig. 4. The encoder community consists of 49 convolutional layers, comparable to the primary 49 convolutional layers within the ResNet50 community37. Downsampling permits deeper layers of the community to collect contextual informa-tion whereas serving to to scale back the quantity of computation. The output of the encoder is (E_ileft( xright)) and x is the enter of the earlier layer. A most pooling layer is inserted between the primary encoder and the second encoder for reaching translation invariance over small spatial shifts within the enter picture, which is extra sturdy. Batch normalization (BN)38 is utilized to the encoders after every time they carry out convolution with the filter financial institution to supply a set of function maps. When the inputs and outputs of ResBlock have the identical dimensions, id shortcuts can be utilized instantly (strong line shortcuts in Fig. 4). And when the scale don’t match (dotted line shortcuts in Fig. 4), the matching of enter and output dimensions is achieved by (1 occasions 1) convolution. When shortcuts cross by means of function maps of various dimensions, they’ve a step measurement of two. A component-by-element Rectified Linear Unit (ReLU)39 is utilized after the shortcuts:
$$start{aligned} p=max {left( 0, pright) } finish{aligned}$$
(2)
the place p is the output produced by two function maps performing element-by-element summation on a channel-by-channel foundation. The aim of utilizing an encoder cascade is to seize a big sufficient receptive discipline to seize semantic contextual info and study wealthy info between pixels inside a picture for pixel-level prediction.
So as to cut back the variety of mannequin parameters and computation, within the encoder community, we cut back the variety of channels within the convolutional layer, thus decreasing the computational overhead of the mannequin with out considerably degrading the mannequin efficiency, shrinking the mannequin measurement, decreasing using runtime reminiscence, and enhancing the inference velocity to make it appropriate for real-time purposes40,41. We additionally preserve the variety of convolutional layer channels in every CBR fixed to optimize community efficiency and cut back mannequin complexity. Holding the variety of channels constant reduces the complexity of function transformation, which not directly improves coaching and inference effectivity42,43.

The overview of improved CBAM. Two sequential sub-modules within the module: spatial and channel. We feed the enter intermediate function map to our module(improved CBAM) and acquire the weighted function maps.
-
(2)
Improved CBAM: CBAM (Convolutional Block Consideration Module) is a straightforward however efficient feed-forward convolu-tional neural community consideration module. Consideration not solely tells us the place to focus, but additionally improves the expression of curiosity44,45. The module focuses on essential options and ignores pointless options by utilizing the eye mechanism.CBAM incorporates two sub-modules, the channel consideration module46 and the spatial consideration module47,48. The channel consideration module learns the “what” to deal with within the channel axis, and the spatial consideration module learns the “the place” to deal with within the spatial axis. Combining these two modules, by studying to emphasise or suppress info, it successfully helps the community to enhance the illustration of the goal and improve saliency function extraction. The construction of the improved CBAM is proven in Fig. 5. Within the improved CBAM, the spatial and channel consideration modules are utilized sequentially to assist the community pay extra consideration to the targets within the intermediate function map. In complicated industrial situations, the pointer contained in the dashboard could be very tiny for the entire picture, and such a element is tough to be attended to by an atypical community. Subsequently the eye mechanism is required to amplify the community’s consideration and studying effort on it. By inserting this module, the next accuracy than the baseline community was obtained within the Pointer-10K dataset49 (see Part “Experiments and result“). For the reason that module is light-weight, the overhead of parameters and computation is negligible generally.
As proven in Fig. 5, given the intermediate function map (I in R^{C occasions Wtimes H}) as enter, the improved CBAM makes use of the spatial consideration module to acquire the spatial consideration weight (W_S in R^{1 occasions W occasions H}), which is multiplied by (W_S) and I to acquire the spatial weighted function map (I^{‘}). Cross it to (feed … to) the channel consideration module to acquire the channel consideration weight (W_C in R^{C occasions 1 occasions 1}), and multiply WC and (I^{‘}) to acquire the channel weighted function map (I^{”}). The method could be summarized as:
$$start{aligned} start{gathered} I^{‘}=W_Sleft( Iright) otimes I I^{”}=W_Cleft( I^{‘}proper) otimes I^{‘} finish{gathered} finish{aligned}$$
(3)
the place (otimes) denotes element-by-element multiplication. Throughout multiplication, spatial consideration is propagated alongside the channel dimension, and channel consideration is propagated alongside the spatial dimension. (I^{”}) is the output of the improved CBAM. Determine 6 depicts the computation course of of every consideration map.

Diagram of spatial and channel consideration sub-module. As proven, the spatial sub-module selects the utmost and common values in all channel dimensions and ahead them to a convolution layer to generate spatial consideration weights; the channel sub-module makes use of max pooling and common pooling with a shared MLP to generate the channel consideration weight.
Improved spatial consideration module
Generally, the content material of curiosity is barely related to some areas of the picture. Subsequently, the spatial consideration mechanism is utilized to attempt to pay extra consideration to semantically related areas relatively than paying the identical consideration to each area within the picture. To acquire the spatial consideration weights, the utmost and common values are first computed on the channel dimension and they’re concatenated to generate spatially wealthy function representations. Pooling operations on the channel dimension can considerably enhance the efficiency of convolutional neural networks (CNNs) and successfully spotlight the semantically informative areas of consideration50. Making use of a convolutional operation on the cascaded function representations generates the spatial consideration weight (W_Sleft( Iright) in R^{W occasions H}), which emphasizes the placement of curiosity and suppresses different areas. The detailed operations are described subsequent.
The spatial info of the function maps is obtained by utilizing the utmost pooling and common pooling operations to generate two 2D function maps (I_{max}^S in R^{1 occasions W occasions H}) and (I_{imply}^S in R^{1 occasions W occasions H}), which characterize the utmost pooled and common pooled options of the function maps over all channels, respectively. They’re then concatenated and convolved by means of a convolutional layer to generate 2D spatial consideration weights. Briefly, the spatial consideration weights are computed as follows:
$$start{aligned} W_Sleft( Iright)&= tanh left( ok^{7 occasions 7}left( Maxleft( Iright) ;Meanleft( Iright) proper) proper) &= tanh left( ok^{7 occasions 7}left( I_{max}^S;I_{imply}^Sright) proper) finish{aligned}$$
(4)
the place (ok^{7 occasions 7}) denotes a convolution operation with a convolution kernel measurement of (7 occasions 7), and (tanh left( bullet proper)) denotes the tanh operate, which is used to generate spatial consideration weights on the function map area. The rationale for utilizing the tanh operate as an alternative of the sigmoid operate is that the sigmoid operate converges slowly, and the tanh operate solves this drawback. The spatial consideration weights are multiplied factor by factor with the enter function map to acquire a spatially weighted function map.
Improved channel consideration module
The channels within the function map mirror the function info within the foreground and background. Subsequently, the channel consideration mechanism is utilized to attempt to pay extra consideration to the function info of curiosity relatively than paying the identical consideration to every channel within the function map. After acquiring the spatially weighted function map (I^{‘} = left[ i_1, i_2, dots , i_C right]), the place (i_j in R^{W occasions H}) denotes the jth channel within the function map (I^{‘}) and C is the variety of channels, the channel consideration weights are generated by exploiting the inter-channel relations of the function map.Every channel of the function map output by the CNN can be utilized as a separate function extractor51, and thus channel consideration could be seen as the method of choosing, given an enter picture, the method of semantic attributes. Channel consideration is complementary to spatial consideration in that they deal with totally different components of the data. We use most pooling and common pooling for every channel to acquire essential cues in regards to the options of the thing of curiosity, avoiding cue omissions that result in coarse channel consideration.The detailed operations are described subsequent.

Diagram of our object heatmap-scalarmap module(OHSM). OHSM has two branches. One department is to generate a warmth map by performing a convolution operation with given function maps. The opposite department is to acquire complete options by world common pooling, generate channel weights by performing 1D convolutions of measurement ok, multiply them element-wise with the enter, after which generate scalar maps by convolution operation and tanh activation operate.
Channel options are first obtained utilizing most pooling and common pooling operations for every channel:
$$start{aligned} I_{max}^C&= left[ v_1, v_2, dots , v_Cright] , I_{max}^C in R^C I_{avg}^C&= left[ u_1, u_2, dots , u_Cright] , I_{avg}^C in R^C finish{aligned}$$
(5)
the place scalar (v_j) is the utmost worth of vector (i_j) and scalar (u_j) is the imply worth of vector (i_j), denoting the jth channel function. The (I_{max}^C) and (I_{avg}^C) denote the maximal channel merging function descriptor and the typical channel merging function descriptor, respectively. These two descriptors are transmitted to a shared multilayer perceptual machine (MLP) to generate the channel consideration weights (W_Cleft( Iright) in R^{C occasions 1 occasions 1}). The MLP consists of a number of hidden layers, and the hidden layer activation applies the Leaky ReLU operate, which is used to resolve the neuron necrosis drawback of ReLU. To stop extreme parameter overhead, the hidden layer activation measurement is ready to (R^{C/r occasions 1 occasions 1}), the place r is the discount ratio. after the MLP is utilized to every descriptor, channel consideration weights are merged and output utilizing element-by-element summation. Briefly, the channel consideration weights are computed as follows:
$$start{aligned} W_Cleft( Iright)&= tanh left( MLPleft( MaxPoolleft( Iright) + AvgPoolleft( Iright) proper) proper) &= tanh left( MLPleft( I_{max}^C;I_{avg}^Cright) proper) finish{aligned}$$
(6)
the place (tanh left( bullet proper)) denotes the tanh operate, which is used to generate the channel consideration weights on the function map area. Be aware that the MLP weights are shared for each inputs. The channel consideration weights are multiplied element-by-element with the sum spatially weighted function map to acquire the output (Aleft( Iright)) of the improved CBAM, which is used as an enter to the decoder D.
-
(3)
Decoder Community D: Decoders within the decoder community up-sample coarse spatial and powerful semantic function maps from the encoder. The high-level summary options are generated into high-resolution decoder-dense function maps by back-convolution, after which batch normalization and ReLU are utilized to every map.The decoder outputs a high-dimensional function illustration (Dleft( Eleft( xright) proper)) enriched with world contextual and semantic info, which is distributed to the goal heatmap-scalar map module. The encoder community and decoder community are thus uneven as a result of non-consistent enter and output sizes of the PIN.
-
(4)
Object Heatmap-Scalarmap Module (OHSM) O: Impressed by ECA-Web52, a channel consideration mechanism is launched to boost the extraction of options and additional enhance the efficiency of our deep CNN mannequin, PIN, as a result of small illustration of pointers within the picture and the over-representation of the background53,54. Since dimensionality discount imposes uncomfortable side effects on channel consideration prediction and capturing the dependencies between all channels is inefficient and pointless52, our proposed OHSM avoids dimensionality discount and employs an environment friendly strategy to seize correlations between channels as a method of producing warmth maps highlighting the placement of the pointer head and scalar maps predicting the place the pointer is pointing. Channel dependency causes every convolutional filter to function utilizing solely the native receptive discipline, and is unable to make the most of contextual info exterior of that area. To deal with this drawback, we use channel common pooling with out dimensionality discount to compress world spatial info into channel descriptors and effectively seize correlations between native channels by contemplating every channel and its ok neighbors.
As proven in Fig. 7, the outcome (X in R^{C occasions W occasions H}) obtained by the element-by-element summation of the output (Aleft( E_1left( xright) + E_2left( xright) proper)) of the improved CBAM and the output (Dleft( Eleft( xright) proper)) of the decoder community serves because the enter to our OHSM.The weights of the channels within the OHSM could be expressed as
$$start{aligned} tau = sigma left( T_kfleft( Xright) proper) finish{aligned}$$
(7)
the place (fleft( Xright) =frac{1}{WH}sum _{i=1,j=1}^{W,H}X_{ij}) is the worldwide channel common pooling, (sigma) is the sigmoid operate, and our OHSM makes use of the banding matrix (T_k) to study channel consideration:
$$start{aligned} T_k = start{bmatrix} t^{1, 1}& dots & t^{1, ok}& 0& 0& dots & dots & 0& 0& t^{2, 2}& dots & t^{2, ok + 1}& 0& dots & dots & 0& dots & dots & dots & dots & dots & dots & dots & dots & 0& dots & 0& 0& dots & t^{C, C – ok + 1}& dots & t^{C, C}& finish{bmatrix} finish{aligned}$$
(8)
(T_k) in Eq. (8) entails (ok occasions C), avoiding full independence between the totally different teams within the equation. Let (y = fleft( Xright)), the burden of (y_i) in Eq. (8) is calculated by contemplating solely the correlation between (y_i) and its ok neighbors:
$$start{aligned} tau _i=sigma left( sum _{j=1}^{ok}{tau ^jy_i^j}proper) , y_i^jin omega _i^ok finish{aligned}$$
(9)
the place (omega _i^ok) denotes the set of ok neighboring channels of (y_i), all of which share the identical studying parameters.
We implement the above technique utilizing a one-dimensional convolution with kernel measurement ok:
$$start{aligned} tau =sigma left( 1D_kleft( yright) proper) finish{aligned}$$
(10)
the place 1D denotes one-dimensional convolution, solely ok parameters are concerned in Eq. 10, which ensures very low module complexity and negligible computational effort, whereas on the similar time offering a major improve-ment in efficiency by capturing native channel correlations to study efficient channel consideration.
This module enhances the power to extract shallow function info, and improves the accuracy of pointer key level and route recognition and enhances the detection impact by fusing the excessive decision of shallow options and the excessive semantic info of higher-level options.
Our PIN is a totally convolutional community (FCN) with twin outputs that may be skilled end-to-end. Convolutional neural networks (CNNs) have been proven to be very efficient in varied domains55,56, primarily because of the truth that
-
Characteristic info in knowledge is extracted by a learnable convolutional kernel with the potential of parameter sharing, which provides the community higher function extraction,
-
The usage of stochastic gradient descent (SGD) optimization to study domain-specific picture options,
-
The flexibility to carry out translation invariance on info corresponding to pictures. Particularly, Absolutely Convolutional Networks (FCNs)57, e.g.,58,59,60 have been proven to attain sturdy and correct efficiency in picture segmentation duties.
Coaching course of
Given a set of RGB picture blocks (G^J = {J_1,J_2, dots ,J_n}), we iteratively take (J_i in R^{W occasions H}, i in left[ 1, nright]), and within the coaching part, PIN takes as enter (J_i^{‘} in R^{W^{‘} occasions H^{‘}}) after affine transformation and produces a set of confidence coefficients representing the route of the pointer models (Phi = (xi _1, xi _2, dots , xi _n)) as output. Let
$$start{aligned} xi _i={x_i,y_i,lambda _i,mu _i,nu _i} finish{aligned}$$
(11)
is the detection results of the ith pointer, the place (left( x_i,y_iright)) is the preliminary coordinate level; (lambda _i in left[ 1, 1right] , mu _i in left[ 1, 1right]) are the scalar parts on the X-axis and Y-axis, respectively; (nu _i) is the boldness coefficient, (i in left[ 1, zetaright]), and (zeta) is the variety of pointers detected within the picture.
Be aware that the variety of pointers (zeta) for a recognized class meter is understood upfront, however PIN itself is unknown about (zeta), and it solely outputs a decided confidence stage for the pointers. The variety of pointers output by PIN could also be lower than or equal to (zeta) because of pointers overlapping one another or pointers overlapping the size resulting in pointers being incorrectly recognized as non-pointers.Our PIN predicted warmth map 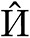 and scalar map (hat{Gamma }) regress to the bottom fact warmth map
and scalar map (hat{Gamma }) regress to the bottom fact warmth map 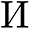 and the bottom fact scalar map (Gamma), respectively.If (nu _i) in (xi _i) exceeds a confidence threshold, then the height in
and the bottom fact scalar map (Gamma), respectively.If (nu _i) in (xi _i) exceeds a confidence threshold, then the height in 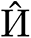 is used because the pointer tip, the place (W^{”} = alpha W^{‘}), (H^{”} = alpha H^{‘}). Scale the coordinates (left( x_i^{‘},y_i^{‘}proper)) of this peak in
is used because the pointer tip, the place (W^{”} = alpha W^{‘}), (H^{”} = alpha H^{‘}). Scale the coordinates (left( x_i^{‘},y_i^{‘}proper)) of this peak in 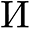 again to (J_i^{‘}). We assign the values on the coordinates (left( x_i^{‘},y_i^{‘}proper)) of the 2 channels in (Gamma) to (lambda _i) and (mu _i), respectively.
again to (J_i^{‘}). We assign the values on the coordinates (left( x_i^{‘},y_i^{‘}proper)) of the 2 channels in (Gamma) to (lambda _i) and (mu _i), respectively.

Annotation of the pattern picture. The picture is from49.
For the bottom fact warmth map 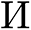 , we take into account the information of the tips to be extra outlined and simple for the community to localize them, whereas different components of the pointers (e.g., the tails) could also be coarse, which makes them tough to be labeled. We initialize
, we take into account the information of the tips to be extra outlined and simple for the community to localize them, whereas different components of the pointers (e.g., the tails) could also be coarse, which makes them tough to be labeled. We initialize 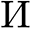 utilizing a clean map full of zeros, and for every pointer tip pixel level (t_i=(x_i,y_i)), we scale it to (t_i^{‘}=(alpha x_i,alpha y_i)), and compute the worth of every pixel (kappa) in
utilizing a clean map full of zeros, and for every pointer tip pixel level (t_i=(x_i,y_i)), we scale it to (t_i^{‘}=(alpha x_i,alpha y_i)), and compute the worth of every pixel (kappa) in 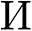 by making use of a 2D Gaussian distribution centered on (t_i^{‘}):
by making use of a 2D Gaussian distribution centered on (t_i^{‘}):
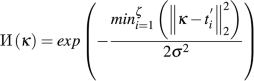
(12)
the place (sigma) is the usual deviation controlling for the width and kurtosis of the distribution curve.
For a floor fact scalar map ({Gamma } in R^{W^{”} occasions H^{”} occasions 2}), we denote the pointer’s pointing route by a clean map ({Gamma }_lambda) and ({Gamma }_mu) of the identical measurement as 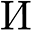 , respectively, the place (lambda) and (mu) denote the 2 scalar parts of the pointer. We derive their values for every pixel recursively:
, respectively, the place (lambda) and (mu) denote the 2 scalar parts of the pointer. We derive their values for every pixel recursively:
$$start{aligned} {Gamma }_{lambda ,i}left( kappa proper) = left{ start{aligned}&lambda _i ~~~~~~~~~~~~~if,,left| kappa – t_i^{‘} proper| le 2sigma , &0 ~~~~~~~~~~~~~~~~~~~~~elsewise. finish{aligned} proper. {Gamma }_{mu ,i}left( kappa proper) = left{ start{aligned}&mu _i ~~~~~~~~~~~~~if,,left| kappa – t_i^{‘} proper| le 2sigma , &0 ~~~~~~~~~~~~~~~~~~~~~elsewise. finish{aligned} proper. finish{aligned}$$
(13)
the place (i in left[ 1, zeta right]), ({Gamma }_{lambda ,i}left( kappa proper)) and ({Gamma }_{mu ,i}left( kappa proper)) denote the 2 channel indication values of the ith pointer at pixel (kappa) for (Gamma), respectively. Then
$$start{aligned} {Gamma }_{theta }left( kappa proper) = left{ start{aligned}&sum _{i=1}^{zeta } {Gamma }_{theta }left( kappa proper) /Omega left( kappa proper) ~~~~~~~~~~~~~if,,Omega left( kappa proper) >0, &0 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~elsewise. finish{aligned} proper. finish{aligned}$$
(14)
the place (theta in left[ lambda , mu right]), superimposing ({Gamma }_lambda) and ({Gamma }_mu) alongside the channel provides (Omega left( kappa proper)):
$$start{aligned} Omega left( kappa proper) = sum _{i=1}^{zeta } gamma left( {Gamma }_{theta ,i}proper) textual content {, the place } gamma left( xright) = left{ start{aligned}&1 ~~~~~~~~~~if ,,x>0, &0 ~~~~~~~~~~elsewise. finish{aligned} proper. finish{aligned}$$
(15)

Low high quality pictures in Pointer-10K49 (blur, scale, and poor illumination).
Loss operate
The coaching goal of PIN is to attenuate the imply sq. error (MSE) loss between the anticipated warmth map 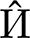 and the bottom fact warmth map
and the bottom fact warmth map 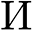 , denoted by
, denoted by 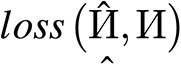 , and the MSE loss between the anticipated scalar map (hat{{Gamma }}) and the bottom fact scalar map (Gamma), denoted by (lossleft( hat{{Gamma }},{Gamma }proper)). The general loss with respect to the coaching epoch is
, and the MSE loss between the anticipated scalar map (hat{{Gamma }}) and the bottom fact scalar map (Gamma), denoted by (lossleft( hat{{Gamma }},{Gamma }proper)). The general loss with respect to the coaching epoch is

(16)
the place Z is the whole coaching epoch and (varepsilon) is the epoch index. we observe that (lossleft( hat{{Gamma }},{Gamma }proper)) converges slower than 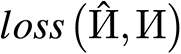 , which tends to make the PIN fall into an area most if no particular remedy is carried out. Empirically, the semantic info on the tip of the pointer is extra simply utilized by the community, whereas the route indicated by the pointer will not be vital for scalar graphs. Subsequently, we use (lambda _1), (lambda _2), and (lambda _3) to steadiness the connection between
, which tends to make the PIN fall into an area most if no particular remedy is carried out. Empirically, the semantic info on the tip of the pointer is extra simply utilized by the community, whereas the route indicated by the pointer will not be vital for scalar graphs. Subsequently, we use (lambda _1), (lambda _2), and (lambda _3) to steadiness the connection between 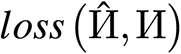 and (lossleft( hat{{Gamma }},{Gamma }proper)), which allows PIN to seek out the pointer tip and the indicated route quicker.
and (lossleft( hat{{Gamma }},{Gamma }proper)), which allows PIN to seek out the pointer tip and the indicated route quicker.
This examine improves the protection and effectivity of inspections in trade and has vital social worth. In important environments corresponding to energy crops and chemical crops, auto-detecting pointer-type meters and pointers can cut back the reliance on handbook inspection, thereby minimizing human error and related security dangers. One of many key determinants in evaluating the success of a proposed system is the accuracy and velocity of detection underneath various environmental situations. Increased detection accuracy and quicker detection speeds make sure that faults are acknowledged and potential disasters and tools failures are prevented. Moreover, the examine demonstrates larger robustness to environmental adjustments, corresponding to adjustments in lighting or picture sharpness, that are frequent challenges in industrial environments. By integrating superior deep studying methods, this analysis contributes to automating industrial duties, finally decreasing operational prices and enhancing useful resource administration. In the long term, the proposed system helps sustainable industrial development by optimizing efficiency, thereby benefiting society as a complete by means of safer and extra environment friendly infrastructure.

The simplified model of OHSM.





